

前言
自从某次尝鲜派后端和 BetaCat 的版本上线之后过了一段时间,服务器监控出现了一些异常,首先是 TCP 连接数 Non-Established 总是有10k~30k并且持续增长。
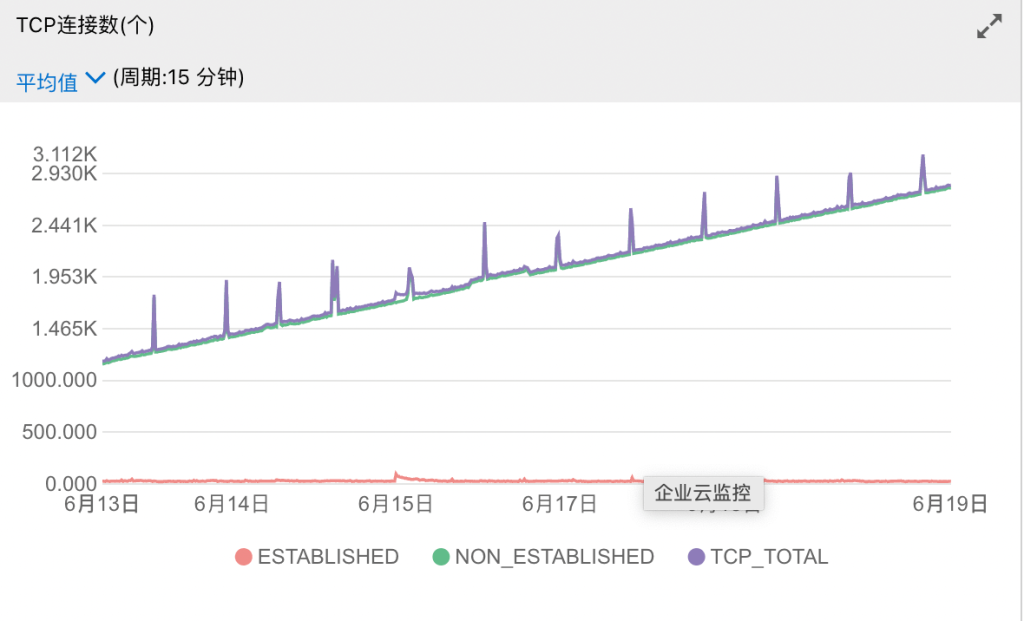
让我一度以为自己的服务器被 SYN Flood 攻击了。
今年WWDC2022前,我将尝鲜派后端和 BetaCat 都改成了微服务,部署到了更高配置的服务器上,但是原来的后端和旧版本的 BetaCat 都没有关闭,前段时间偶然检查内存占用情况,发现几乎处于闲置状态的后端内存占用居然达到了400MB,BetaCat 也莫名其妙被 Kill 掉了,后来检查日志发现是 OOM 了,直观感觉是出现了内存泄漏的问题。
检查新服务器上微服务的内存占用情况,发现内存占用率变化呈阶梯上升的趋势,并且在 WWDC 结束后三天,网站访问了显著下降之后内存占用率竟然还居高不下,于是打算使用 Go 自带的 pprof 来检查内存泄漏情况(期初我还不知道 Go 的协程也会泄漏)。
debug 过程中发现后端和 BetaCat 都有严重的内存泄漏问题,已及时修复完毕。
本文数据来源为后期复盘问题时重新搭建的泄漏模型,只启动后端,在没有用户访问的情况下空跑5天。
准备工作
启动 pporf 非常简单,对于 Gin 框架的应用,只需要在 route 中注册 pprof 路由,
r = gin.New()
pprof.Register(r)即可通过浏览器访问 /debug/pprof 查看堆栈分配、正在运行的协程数量。
对于非 Gin 框架的应用,在 main 函数中加入下列代码
import (
"net/http"
_ "net/http/pprof"
)
func main() {
// ...
go func() {
log.Println(http.ListenAndServe(":6060", nil))
}()
// ...
}通过浏览器访问 ip:6060/debug/pprof 查看堆栈分配、正在运行的协程数量。
Debug 过程
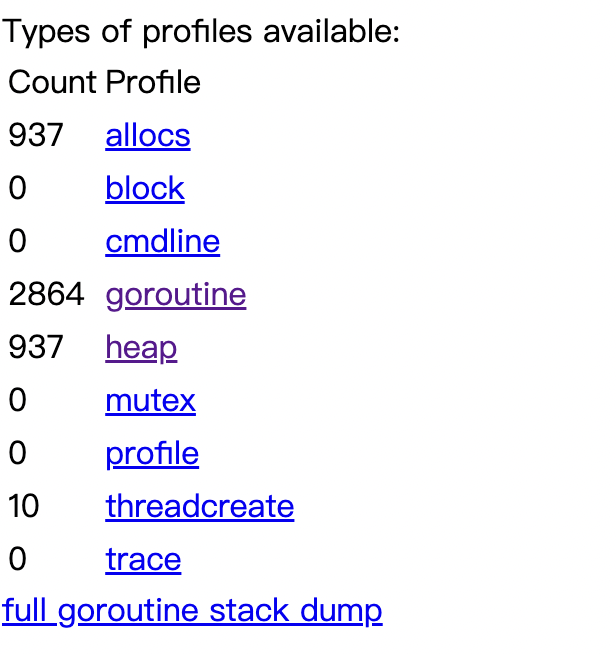
进入 pprof 页面,发现 Goroutine 数量非常大,该后端几乎没有任何用户访问的情况下在启动5天后竟然产生了2.6k个协程。
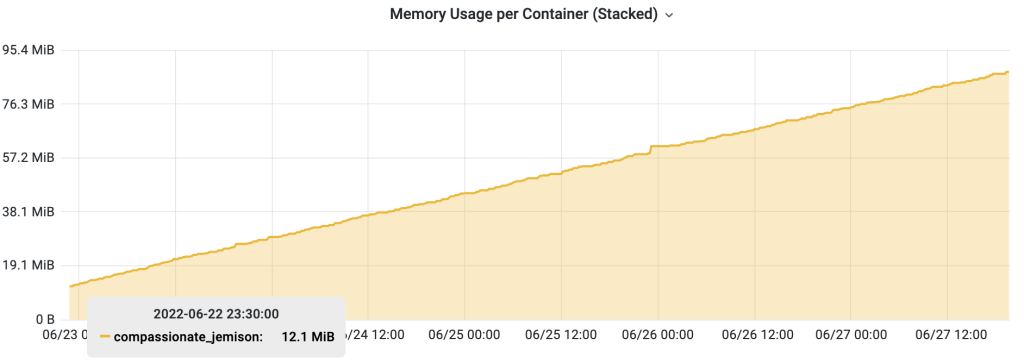
检查 Grafana 的监控记录,非常经典的内存泄漏曲线,从启动时的12MB,增长到五天之后接近100M。
进入 Goroutine 的 profile 页面

发现有 2.8k 个协程卡在 readLoop 或 writeLoop 中,去 Go 的文档库找 readLoop 和 writeLoop 的实现
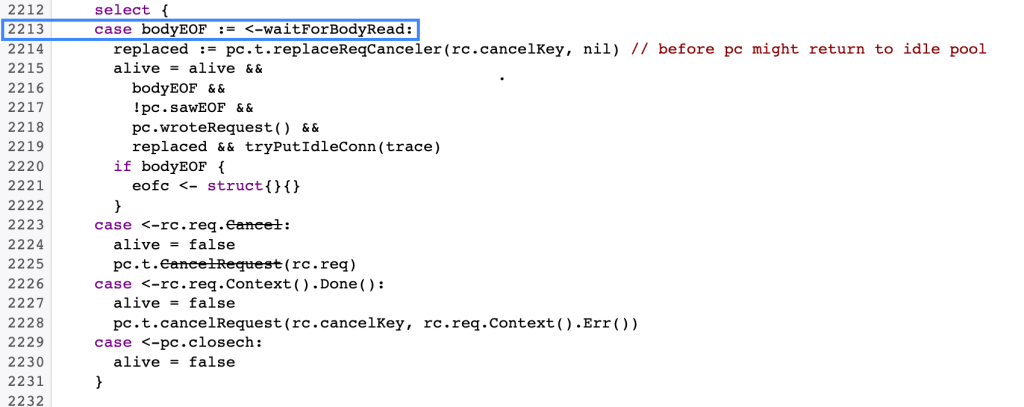

发现协程被阻塞在了 waitForBodyRead 上,大概是因为某处请求忘记 defer resp.Body.Close() 导致的,于是检查了全部涉及到 resp.Body 的代码,发现该关的都关了,居然还在泄漏,再排查所有涉及到 http Request 的代码,发现有一处 req 因为没有用到 resp 的 body 如下图:

于是我直接用 _ 接收了返回值,就更没有 defer Close 了,抱着试一试的心态,接受了 resp 并做 defer Close,将服务上线到正式环境跑了几天,内存占用率变化如下图:
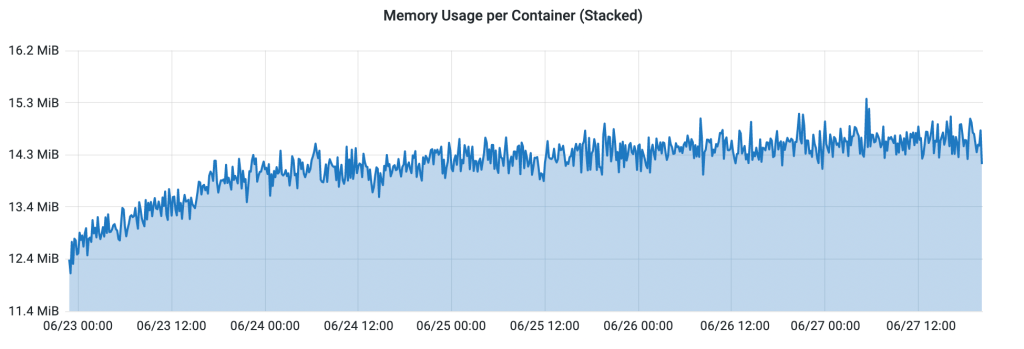
五天以来内存占用率基本维持在16M以下,再检查 pprof 页面,

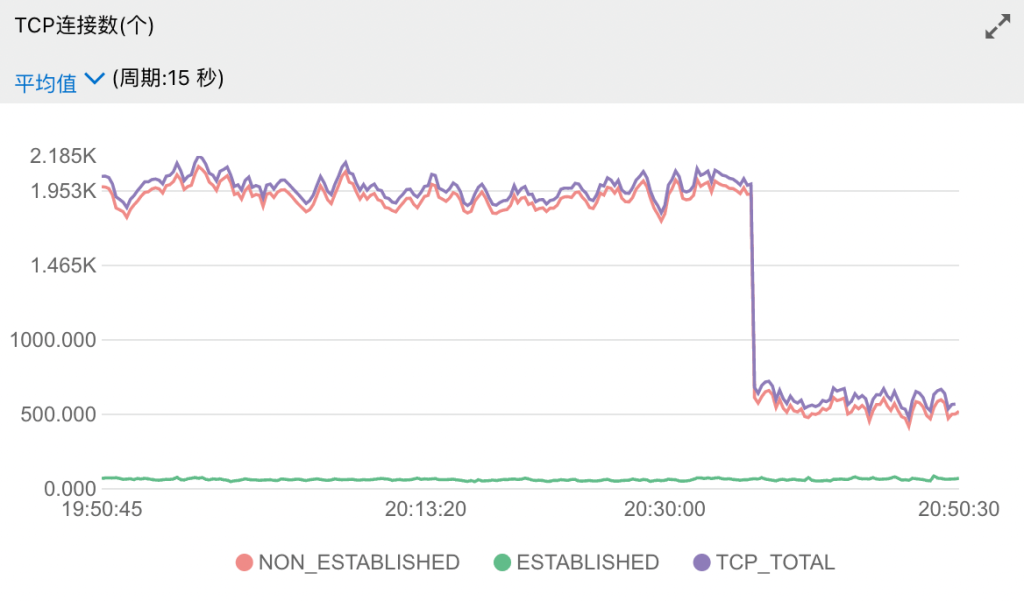
协程数量恢复正常了,服务器监控指标关于 Non-Established 的数量也显著下降。
通过 pprof 的 heap 分配情况,还发现了一些其他的内存泄漏问题,比如文件打开之后忘记 defer Close 之类的,举一反三,我检查了所有 Open 函数的 defer Close 情况,修复了其他内存泄漏的问题。
通过上述手段,成功解决了这次 Go 的内存和协程泄漏问题。
参考文档
- go (*persistConn).writeLoop 导致goroutine泄漏: https://www.jianshu.com/p/ef4c605595c0
- goroutine leak in net/http.(*persistConn).writeLoop #473:
https://github.com/distribution/distribution/issues/473 - Go http request 引起的 goroutine 泄漏: https://sanyuesha.com/2019/09/10/go-http-request-goroutine-leak/
评论 (0)