

很荣幸能与大家进行实验交流
一、原始代码
我们先来回顾一下实验的原始代码
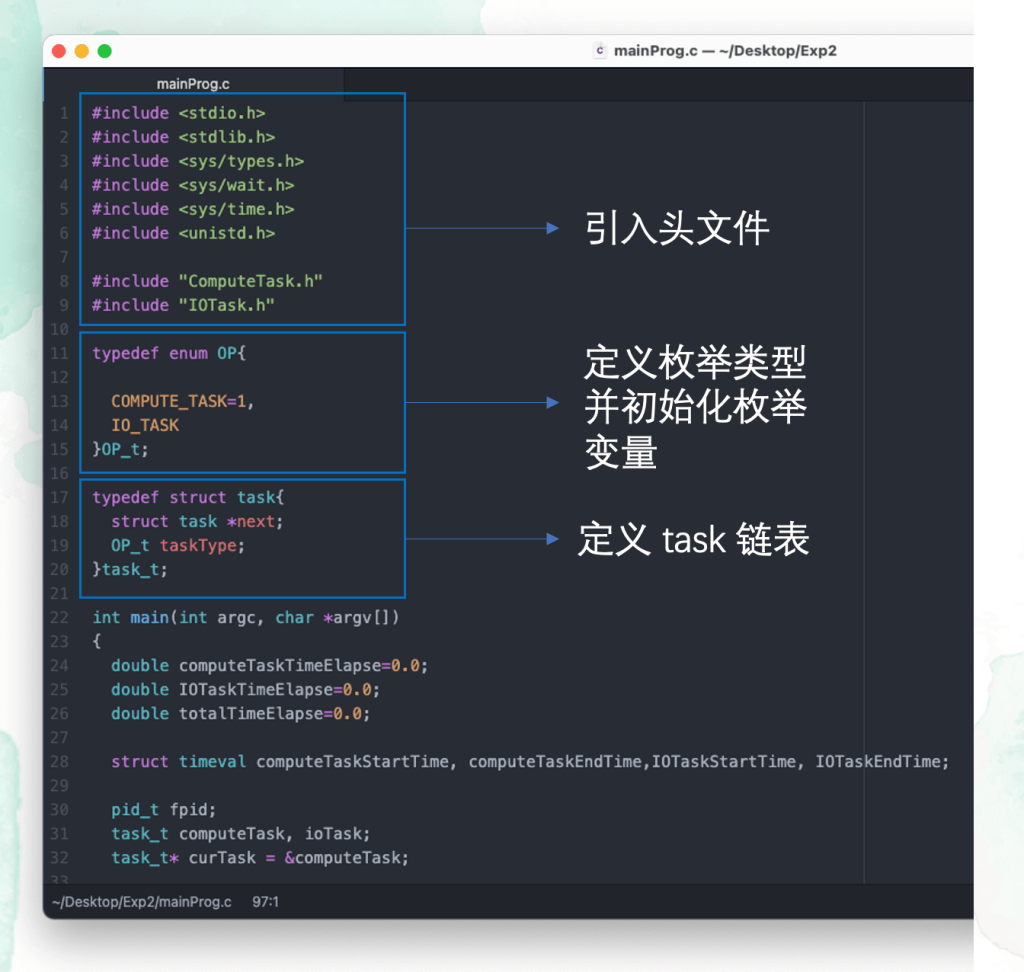
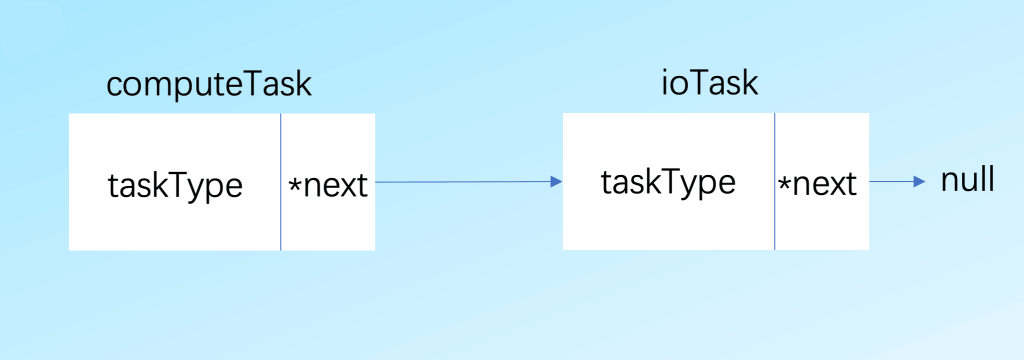
这里创建的链表结构如下
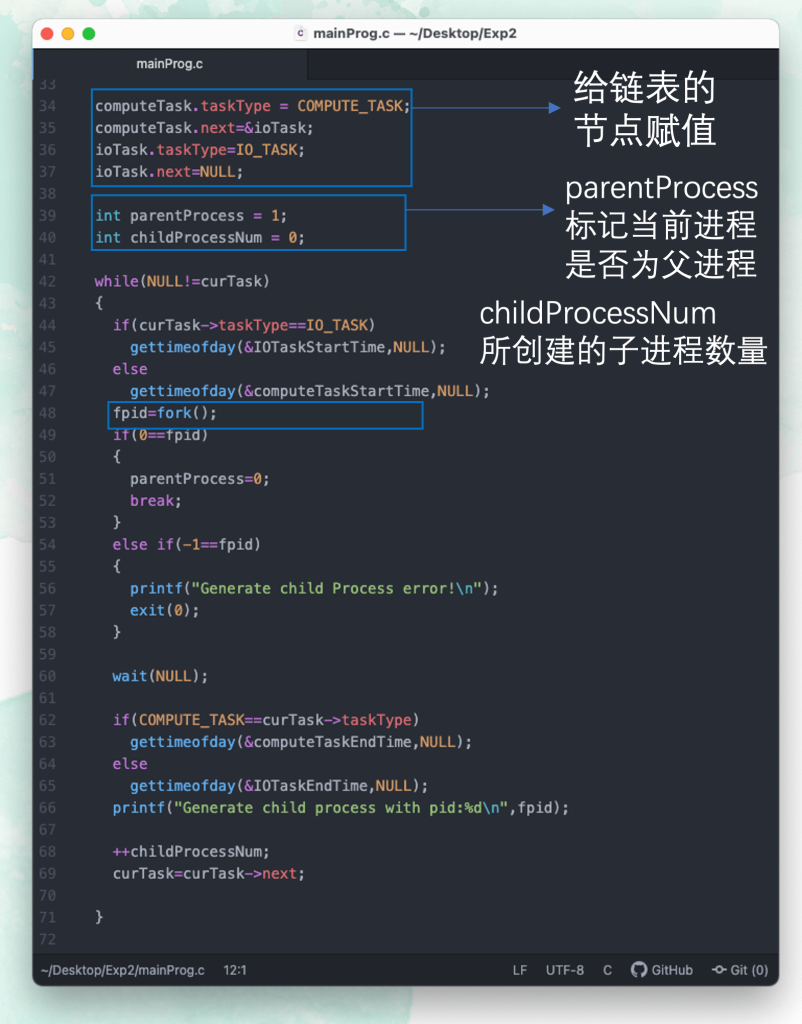
fork(); 函数原型为
#include<unistd.h>
pid_t fork();fork(); 函数的特性是一次调用两次返回,它具有三种返回值。主进程里返回所创建的子进程PID,若子进程创建失败则返回 -1,在子进程中返回0。创建的子进程将会从fork();的下一条命令开始执行程序。

wait(); 函数原型
#include<sys/wait.h> pid_t wait(int *status);
传入一个整形指针用于接收进程的退出状态,函数的返回值是进程的 PID(int),暂停程序直到子进程退出。
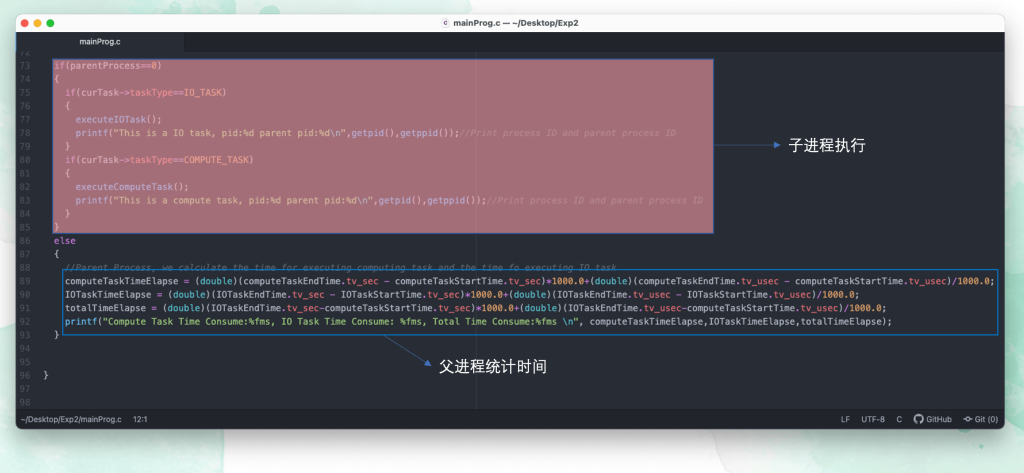
所以这个顺序执行程序的逻辑如下
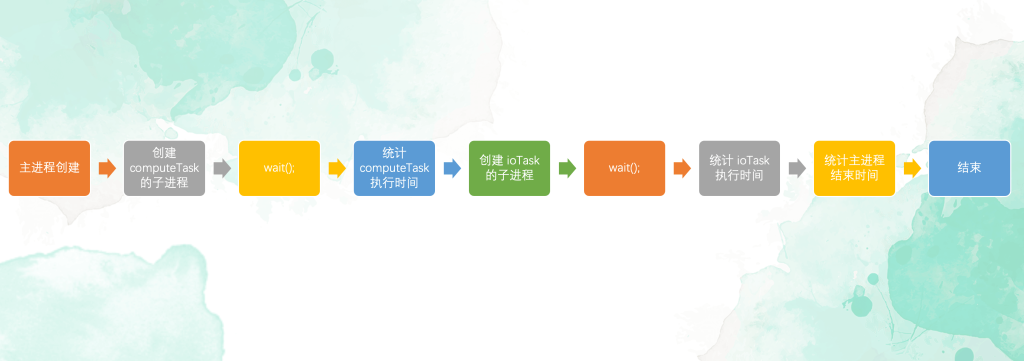
可以看到中间有两次 wait(); 程序的执行效率较低,下面我们将这个程序改造为并发程序。
二、并发代码
在顺序执行中,出现了两次等待的过程,那么我们的思路就是让主进程在创建子进程的之后无需等待,直接创建,创建了两个子进程后再让主进程等待两个子进程退出,当所有子进程都退出以后,主进程执行完毕。
为了实现这个思路,我们的改造如下
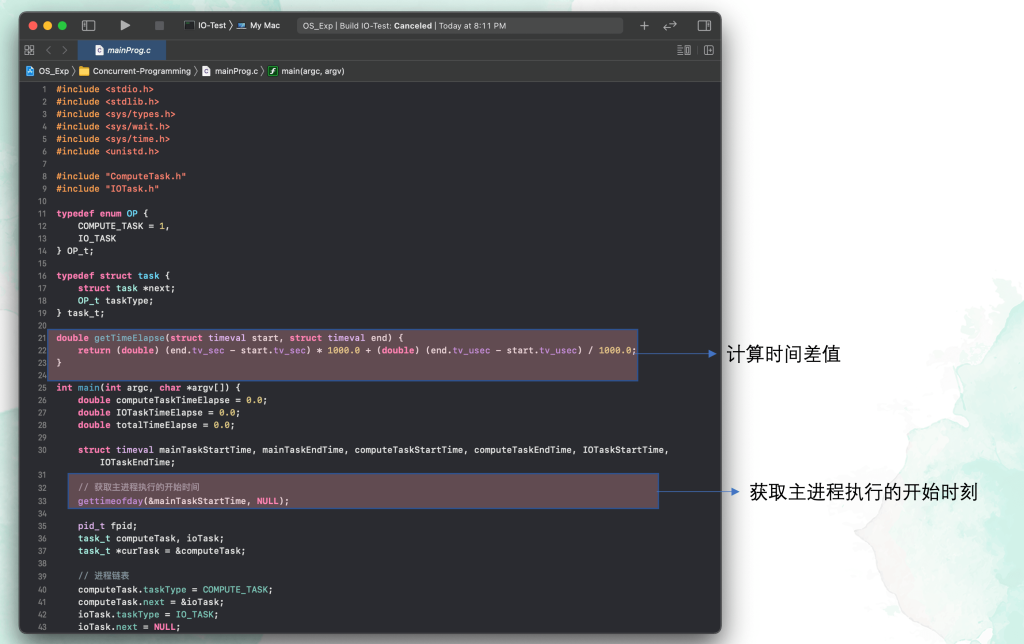
需要在原来的 while 创建进程的循环过程中将 wait(NULL); 去掉,那么这个时候主进程就会直接创建好两个子进程。
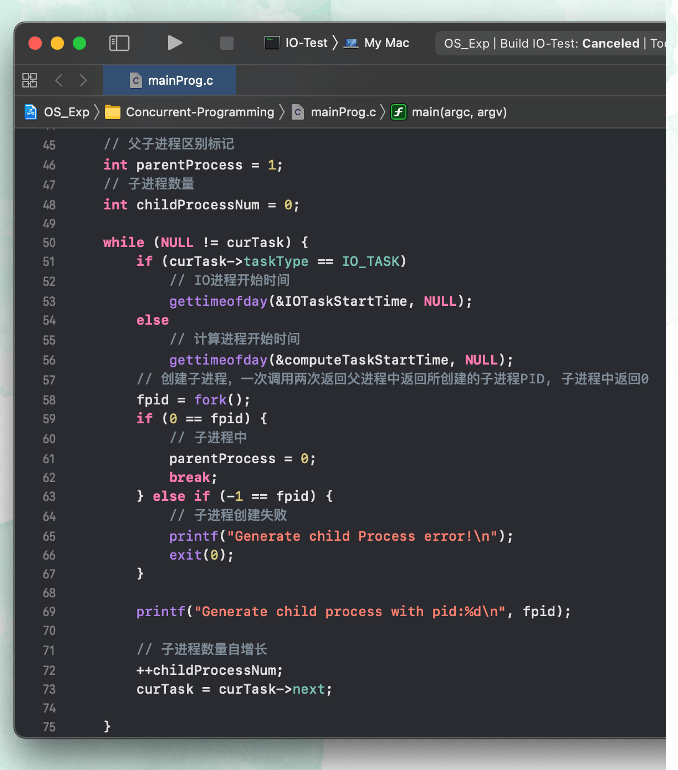
创建完成后,我们不能马上让主进程结束,否则的话我们没办法正确的测量出子进程执行的时间,除此之外,这些子进程,因为没有被主进程的 wait(); 处理,还将变为僵尸进程,浪费操作系统的可用进程编号,直至系统重启。
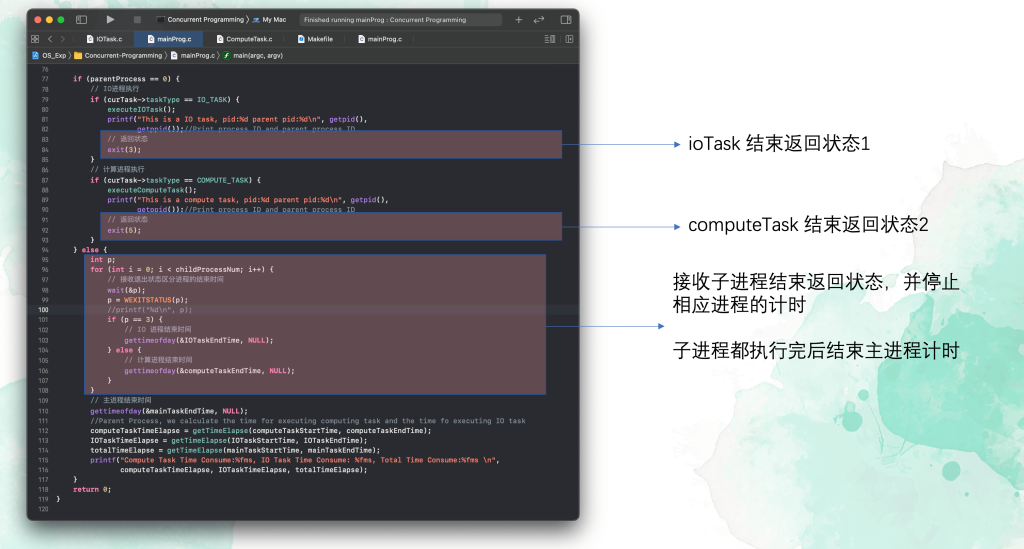
所以我们考虑在主进程结束前对已退出的子进程使用 wait(); 进行处理。因为我们这里需要实现计时的功能,如何才能判断当前退出的任务,以结束对它的计时?
我采用的方案是在子进程中使用 exit(); 退出,并返回不同退出状态。
在主进程中,我们可以通过 wait(&p); 使 p 接收到退出的信息。
注意 wait(&p);传给 p 的值包括子进程是正常退出还是被非正常结束的,以及正常结束时的返回值,或被哪一个信号结束的等信息。
由于这些信息被存放在一个整数的不同二进制位中,因此我们需要通过 WEXITSTATUS(p)将我们所需要的 exit 值取出。
这样再对 p 进行判断,例如我在 computeTask 中的退出返回状态是2,当我判断到 p == 2 时,就结束对 computeTask 的计时,这样就能完成实验的要求。
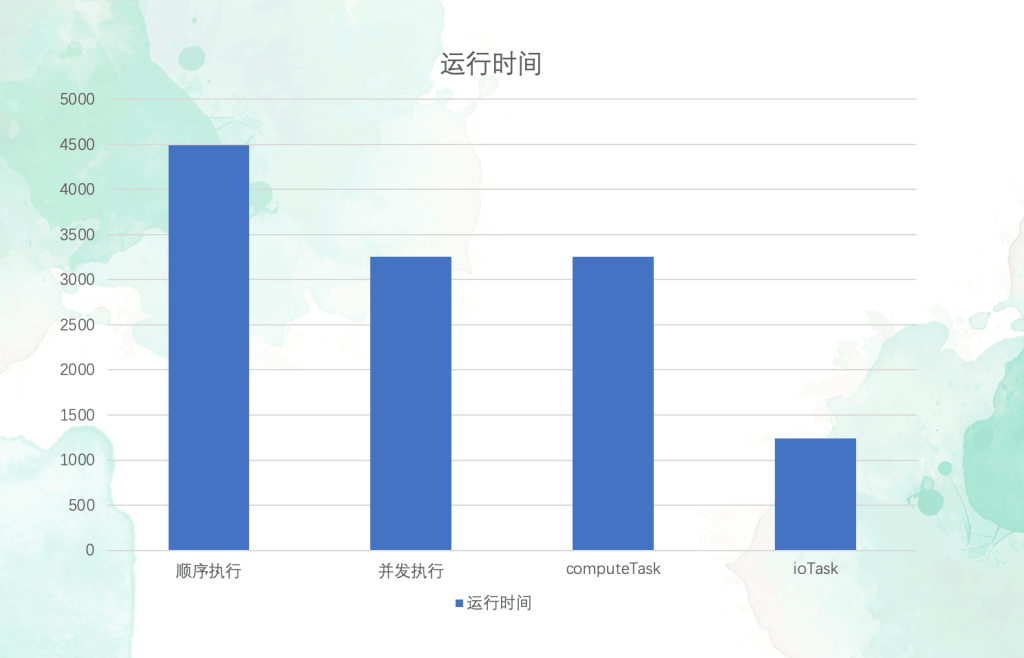
三、运行比较
改好之后 make,再运行。结果非常的 amzing,并发执行的时间几乎等于最慢的那个子进程,最快的子进程则提前结束了运行。
四、代码仓库
并发代码详见 https://github.com/0xJacky/OS_Exp/tree/main/Concurrent-Programming
评论 (0)